

Published on Mon, Oct 31, 2022 by Étienne Brouillard
Part of my work is to describe and explain technically how to achieve such and such use case using AWS. I've done numerous things across the years but this has been a recurrent ask: how could we build a realtime speech to text processing pipeline using Amazon Transcribe. This article is about just this: describe how to build a simple yet extremely efficient (read: cost-effective) realtime speech to text in AWS.
At high level, what should this solution should do?
- Through a simple frontend capture the audio provided by a microphone,
- Use Amazon Transcribe to do speech to text in realtime,
- Broadcasts the conversation stream to all connected clients of a conversation,
- Uses Serverless and PaaS components,
- Costs less than 10$ a month excluding Amazon Transcribe.
This demo uses a web application to capture the audio but the idea is the web application server can deal with any source of audio as long as it's streamed into correctly.
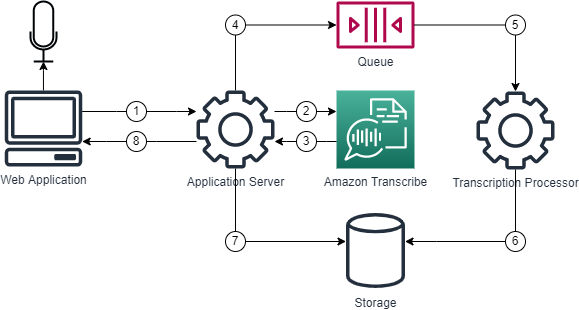
The realtime capture of audio is sequenced as such:
- A user triggers an audio capture using the web application, the web application opens a websocket for the audio with the application server
- The web application captures the microphones audio and streams the audio to the application server and then to Amazon Transcribe
- Amazon Transcribe, using a bi-directional websocket, returns the transcription in realtime for that audio stream. The application server waits for Amazon Transcribe to stabilize
- Once Amazon Transcribe stabilizes, the transcription is pushed in a queue
- A transcript processor handles the speech to text transcripts
- The new transcript to be added to a conversation is persisted to storage
- The application application server reads at interval the last 2 minutes of a conversation from the storage
- The last 2 minutes are returned to the web application using a state update websocket
In order to implement the solution and meet the efficiency criteria the design translates into this:
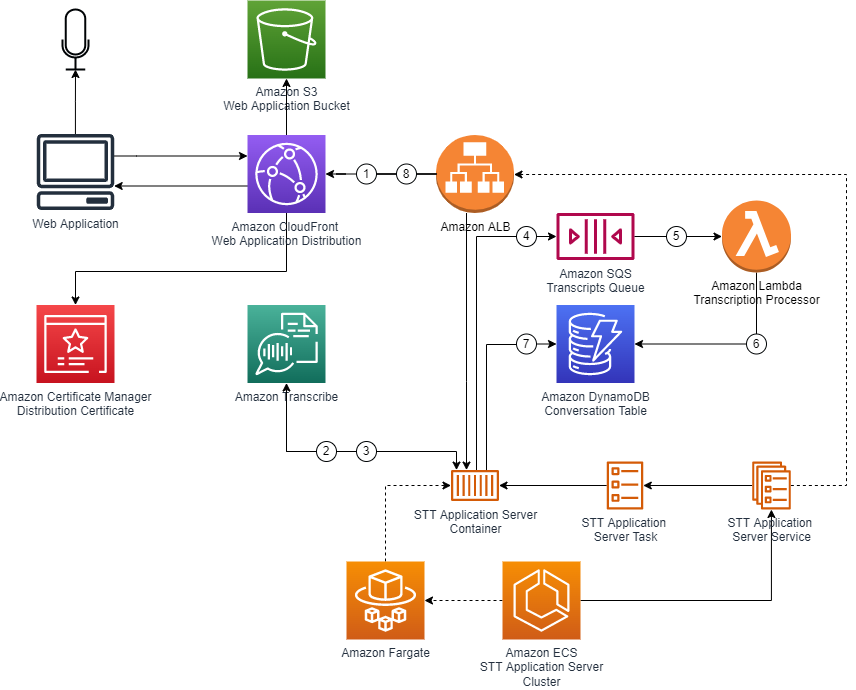
The web application is served using Amazon CloudFront and an S3 Bucket. The application server is hosted on AWS Fargate compute using Amazon ECS and load balanced using Amazon ELB. The transcript processor reads of an Amazon SQS Queue and stores conversations in an Amazon DynamoDB table. Which is then fed back to the web applications connected to a specific conversation.
For the curious minds, the application, as designed above, is available here.
This is all fine and jolly but let's look on how each of the moving parts are built.
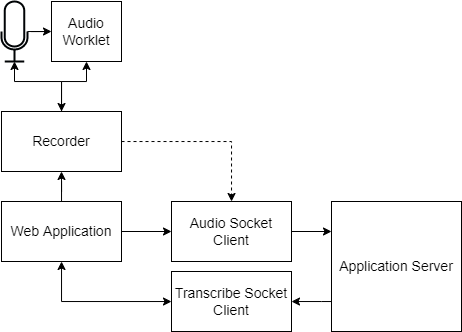
The web application is built on React using the Redux toolkit and it uses an AudioWorklet to capture the audio stream from the selected microphone. An AudioWorklet is a specialized lightweight webworker which lets developers hook onto the rendering pipeline of a browser.
Once the worklet is properly hooked, the audio that is captured is resampled to 44100KHz if necessaery and encoded into PCM format on the browser side. This ensures that the application server receives the audio in a format which is compatible with Amazon Transcribe. To communicate with the application server, the web application opens two websockets: one short running socket for audio streams which stays open at most 30 seconds and a second one which receives conversation updates every 10 seconds.
The web application's, using the audio worklet, high level design looks like this:
This component is built on top of an ExpressJS server. Web sockets are handled using the ws NodeJS module. The integration with Amazon Transcribe service is achieved using direct websockets instead of using the SDK helpers.
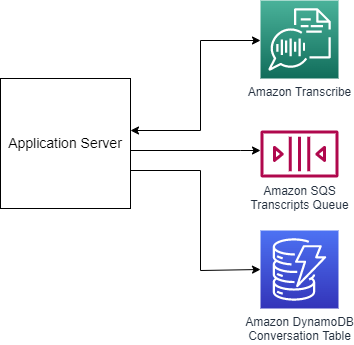
Once a client has connected an audio stream through websocket, the application server opens a new websocket with Amazon Transcribe and sends in the audio. When the transcription stabilizes (when Amazon Transcribe declares it has reached its peak confidence for a sequence of speech) the application server pushes the transcipt to an SQS queue for processing. The application is server runs on ECS/Fargate and is distributed using Amazon CloudFront targetting an Application Load Balancer.
It provides 3 endpoints:
- /api/stt/healthcheck Returns a status code 200 with the message "Yes, I'm ok".
- /api/stt/transcribe Websocket endpoint which receives audio input. The audio has to be encoded in PCM format and the query parameter sampleRate should match the audio streamed in.
- /api/stt/connect Websocket endpoint which updates the connected clients every 10 seconds with messages processed in the last two minutes. The data is acquired from a DynamoDB table.
A simple Lambda function connected to the SQS queue picks a speech sequence and stores the data in a new row in a DynamoDB table, the same which is used by the application server to read conversation updates.
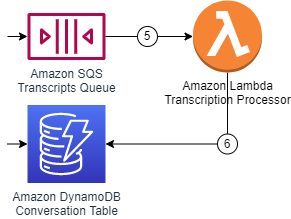
Transcripts are stored in an SQS queue and the Lambda Function pulls messages from the queue. The partitionning on the DynamoDB Table is done on the conversation ID and the sorting key is set on the timestamp.
Of course, this is just a start. By streaming the stabilized speech to text output out of the DynamoDB, it would be possible to add sentiment detection in a hot path and intent detection in a warm path mode. The design at this point is rather demo quality than production ready.
- Handle your Lambda Function and ECS task definitions as build items rather than configuration targets. By doing so I've been able to correctly use Code Deploy features which greatly simplified the continuous delivery automation.
- Some of the SDK for Amazon Transcribe aren't quite easy to understand and therefore the "old school" way of using direct web socket to the service just made things way simpler.
- Using audio worklets just prove to be easier than I initially thought.